DPark 漫谈 -- RDD
注: 本篇是 DPark 漫谈系列的第二篇.
RDD from scratch
RDD(Resilient Distributed Dataset)是 DPark 的核心概念。 它是一个分布式的惰性的数据集,上篇 中我们提到可以自己构造一个 LazyData,并为其添加 map 等接口就可以得到一个类似 RDD 的东西,现在我们就来尝试一下, 我们在这里要实现的 TextFileRDD(之所以取这个名字是为了和 Dpark 兼容), 这个 RDD 的作用是从文件系统读取文件,并进行数据划分。
基本的 RDD
首先我们需要知道文件的路径以及分块的大小,这样我们就可以把一个大文件分成多个小块来处理 (DPark 中把一个分块称之为 split),如下所示,我们把文件按照 splitSize 划分为 n 块儿。你可能注意到这里 splitSize 的命名方式是驼峰式的,我猜想是为了和 Spark 保持一致吧,后面我们会看到很多 RDD 的接口都是驼峰的方式。
class Split(object):
def __init__(self, index):
self.index = index
def __str__(self):
return 'Split<%s>' % self.index
class TextFileRDD(object):
DEFAULT_SPLIT_SIZE = 64 << 20 # 64M
def __init__(self, path, splitSize=None):
self.path = path
if splitSize is None:
splitSize = self.DEFAULT_SPLIT_SIZE
self.splitSize = splitSize
size = os.path.getsize(path)
n = size / splitSize
if size % splitSize > 0:
n += 1
self._splits = [Split(i) for i in range(n)]
@property
def splits(self):
return self._splits
这里的 split 只是一个简单的索引,当调度程序要计算该 RDD 的一个分块时, 会调用它的 compute 方法来获得一个分块的元素。由于 DPark 在处理文件时是按行来处理的, 所以当一个 split 的 end 边界值在文本行的中间位置时,该 split 会读取完整的行, 相应地,下一个 split 在读取数据时,要跳过(skip 变量的意义)已经被上一个 split 读取的部分。
def compute(self, split):
with open(self.path) as f:
start = split.index * self.splitSize
end = start + self.splitSize
if start > 0:
f.seek(start - 1)
ch = f.read(1)
skip = ch != '\n'
else:
f.seek(start)
skip = False
for line in f:
if start >= end:
break
start += len(line)
if skip:
skip = False
else:
yield line
添加 map 接口
现在我们有了一个 RDD 但是没有为其增加一些编程接口以方便我们使用, 下面就来实现一个简单的 map 接口,该方法的返回值仍然是一个 RDD (即 MappedRDD)。
class TextFileRDD(object):
...
def map(self, f):
return MappedRDD(self, f)
class MappedRDD(object):
def __init__(self, prev, f):
self.prev = prev
self.f = f
def __str__(self):
return 'MappedRDD'
@property
def splits(self):
return self.prev.splits
def compute(self, split):
return (self.f(x) for x in self.prev.compute(split))
$ python src/rdd.py
TextFileRDD
======= Split<0> =======
['Structure and Interpretation of Computer Programs\n', 'How to Design Programs\n']
======= Split<1> =======
['Python Programming: An Intro to CS\n', 'Concepts, Techniques, and Models of Computer Programming\n']
======= Split<2> =======
['On Lisp\n']
MappedRDD
======= Split<0> =======
[50, 23]
======= Split<1> =======
[35, 57]
======= Split<2> =======
[8]
RDD 的特性
虽然我们只是实现了两个简陋的 RDD,但是我们还是要努力来总结一下 RDD 有哪些共性,
- RDD 可以由两种方式创建:1)存储设备中的数据(e.g 文件);2)其他 RDD(e.g map 操作)。
- RDD 并不是一个计算好的数据集合,它只是包含了
源数据(lineage,也翻译叫血统)是什么,以及如何计算, 并在需要的时候通过上面的信息计算数据集合。这样的一个好处就是当一个分块丢失时, 我们只需要根据这个分块的血统信息,重新构造出这部分数据。 - RDD 的分块信息,即有 split 相关的信息。
目前,我们差不多可以得到这么多信息,下面是我从 Spark 代码(很遗憾,DPark 的代码注释信息比较少) 中摘出来的关于 RDD 的注释,前三个我们的例子中都有涉及,但是最后两个并没有接触到,这是因为:
- 我们还没有实现 key-value 相关的操作(e.g. reduceByKey 就用到了 hash-partition)
- 关于 prefered locations,我们代码中也没有体现。但这的真实环境中比较重要, 例如我们可以得到一个文件在分布式文件系统中的位置,从而可以在运行的时候, 让任务运行在文件所在的机器上,提高系统性能。
A Resilient Distributed Dataset (RDD), the basic abstraction in MDpark.
Each RDD is characterized by five main properties:
- A list of splits (partitions)
- A function for computing each split
- A list of dependencies on other RDDS
- Optionally, a Partitioner for key-value RDDs (e.g hash-partitioned)
- Optionally, a list of prefered locations to compute each split on
我们自己的尝试就到这里停止了,下面我们通过分析词频统计的例子, 来看看 DPark 中的不同 RDD。
词频统计剖析
上篇结束时,我们给出了一个词频统计的示例, 当时并没有解释其细节,这里我们将剖析其运行过程。
# coding: utf-8
# file: wc.py
import dpark
def parse_words(line):
"""
解析文本行,提取其中的word,并计数为1.
注意:
- 这里假设word是由于英文字母组成的字符串.
- 该函数没有优化速度.
"""
for w in line.split():
if w.isalpha():
yield (w, 1)
def main():
dc = dpark.DparkContext()
options, args = dpark.optParser.parse_args()
file_path = args[0]
data = dc.textFile(file_path, splitSize=2<<20)
wc = data.flatMap(parse_words)\
.reduceByKey(lambda x, y: x + y)\
.top(10, key=lambda x: x[1])
print wc
if __name__ == '__main__':
main()
其 RDD 的逻辑图如下所示,图中的例子是伪造的,主要是为了画图方便:
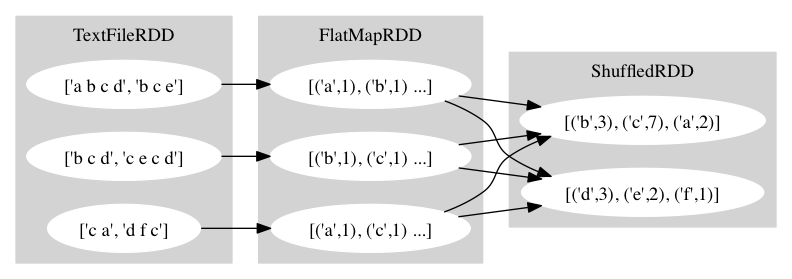
下面我们从 main 函数开始解释每一行的含义。
-
dc = dpark.DparkContext(),DparkContext 是获得 DPark 功能的主要入口, 它设置了 DPark 一些重要的属性,并且可以用来创建 RDD 和广播一些大的数据集。 -
接下来两行利用了的 optParser,来获得我们从命令行传入的文件名称。 关于命令行参数需要注意的是 DPark 的所需要的参数要放在自己应用的参数前面。 例如,我们可以
python wc.py -m mesos shakespeare.txt这样调用, 但是不可以python wc.py shakespeare.txt -m mesos, 因为 DPark 的参数解析器看到第一个不能识别的参数时就会放弃对后面参数的解析, 具体原因参见。 -
data = dc.textFile(file_path, splitSize=2<<20),textFile 函数从 moosefs 文件系统或者本地文件系统读取文本文件,并返回一个 RDD。这里返回的是 TextFileRDD。 由于 RDD 都是惰性计算的,所以这个时候并没有进行任何数据的计算,只是生成了一个 TextFileRDD 实例,并在设置了分块大小等参数。这里为了体现出分块的效果, 我们设置为 2M (因为我们的测试文本集只有 4.3M)。实际应用中这个参数的 默认值为 64M。 -
flatMap(parse_words), flatMap 是 RDD 的一个方法,其返回值是 FlatMapRDD。 faltMap 的效果可以参考上篇中的习题2, 熟悉函数式语言的同学应该对这个方法比较熟悉。 -
reduceByKey(lambda x, y: x + y),其返回值是 ShuffledRDD, 这是我们遇到的第一个关于 key-value 的接口,其作用是把前一步骤中的数据按照 key 进行合并操作,合并的方式就是我们传给它的那个 lambda 函数。另外,该方法在本地会先执行合并操作,然后把合并的结果按照 hash-partition 发送给不同 reducer 进行最终的合并操作。大家可能注意到了,图中 reducer 的个数和前面不一样了,一般来说 reducer 的个数和 mapper 的个数是不一样的, reduceByKey 也提供了一个参数让我们可以改变 reducer 的个数, 但是我们不能把它设置的过大,因为每个 mapper 都要和每个 reducer 通信, 这会增加 IO 和内存开销,所以默认情况下的 reducer 个数是 12 个, 这个对于有些应用来过于小了,导致任务运行太久,所以当你看到你的任务在 reducer 花的时间过多时,可以考虑增加这个参数。 -
top(10, key=lambda x: x[1]),获得 top 10 的单词,这个函数会触发整个 DPark 程序的执行,该方法的实现大致逻辑就是先在每个 Split 拿到 top 10 的数据, 然后从这些临时的优胜者中算出最终的 top 10。图中并没有画这个步骤, 因为这个函数会触发 DPark 执行之后,我们得到的就是 Python 的数据了, 而不再是 RDD 了。
RDD 接口及其应用
RDD 的提供了丰富的编程接口(相对于 Hadoop MR 而言),可以让我们灵活的处理数据。 其接口主要分为两大类:
- transformation,例如 map、filter、reduceByKey,这类接口主要是通过变化 生成新的 RDD,由于 RDD 是惰性的,这时候不会进行真正的计算。
- action,例如 top、count、saveAsTextFile,这类接口会触发 RDD 的计算, 并把结果返回给调用程序,或者写入文件。
关于这些接口的具体含义请参考:
你可能注意到了 DPark 文档 中提到了窄依赖、宽依赖、job、stage、task 等概念,别担心我们会在下一篇中介绍这些, 这些对于理解性能和最终的执行方式有关。对于写一个 DPark 程序,我们暂时可以不管这些, 我希望大家在看完本篇后,就可以处理一些简单的任务了。
应用
- 问题场景
假设我们有截止到今天的所有老用户的集合,以及今天的所有用户集合,请问如何得到出今天的新用户?
- 换个方式描述
我们把今天的所有用户集合记为 users,老用户集合记为 old_users, 那么今天的新增用户就是 users - old_users,即我们现在的问题是 如何求两个大集合的差集。
题外话:刚开始我们的思路是用 bloomfilter 检测当天的用户是否为新用户,但是我们 bloomfilter 服务要求并发度控制在 5 以下,不然会把服务器的 CPU 跑满,这个并行度太低了,所以就用了 DPark。
- 代码
# coding: utf-8
import dpark
def set_diff(rdd1, rdd2):
"""
Return an RDD with elements in rdd1 but not in rdd2.
"""
pair_rdd1 = rdd1.map(lambda x: (x, None))
pair_rdd2 = rdd2.map(lambda x: (x, 1))
return pair_rdd1.leftOuterJoin(pair_rdd2)\
.filter(lambda x: not x[1][1])\
.map(lambda x: x[0])
if __name__ == '__main__':
rdd1 = dpark.parallelize([1, 2, 3, 4])
rdd2 = dpark.parallelize([3, 4, 5, 6])
diff = set_diff(rdd1, rdd2)
rs = diff.collect()
assert sorted(rs) == [1, 2] # DPark 不保证顺序
这里我就不逐行解释了,对于这个程序的理解留作练习吧,不过我还是要给两个建议:
- 多参阅 DPark 文档
- RDD 有一个
take(n)方法,这个方法可以返回 RDD 的前 n 个元素。大家如果不理解上面的程序, 可以修改上面的代码, 打印出每个 RDD 的元素看看是什么样子的。
小结
在这里我们先尝试了实现一些简单的 RDD,从而理解其工作的原理,然后总结归纳出一些信息, 再来和实际情况对比,发现我们的理解中的不足。然后我们剖析了词频统计的例子, 同时给出了 RDD 接口的一个应用示例。
练习
- 执行上面求集合差集的程序,并把玩它,直到弄懂。
- 写 DPark 程序求每个 url 的平均响应时间,假设我们都数据格式如下所示
url response_time
www.douban.com 300
book.douban.com 700
www.douban.com 340
...

